
FastAPI vs Django in 2026: I Moved 3 Production Services — Here’s What Happened
A Python Tech Lead’s honest breakdown after migrating real services from Django to FastAPI

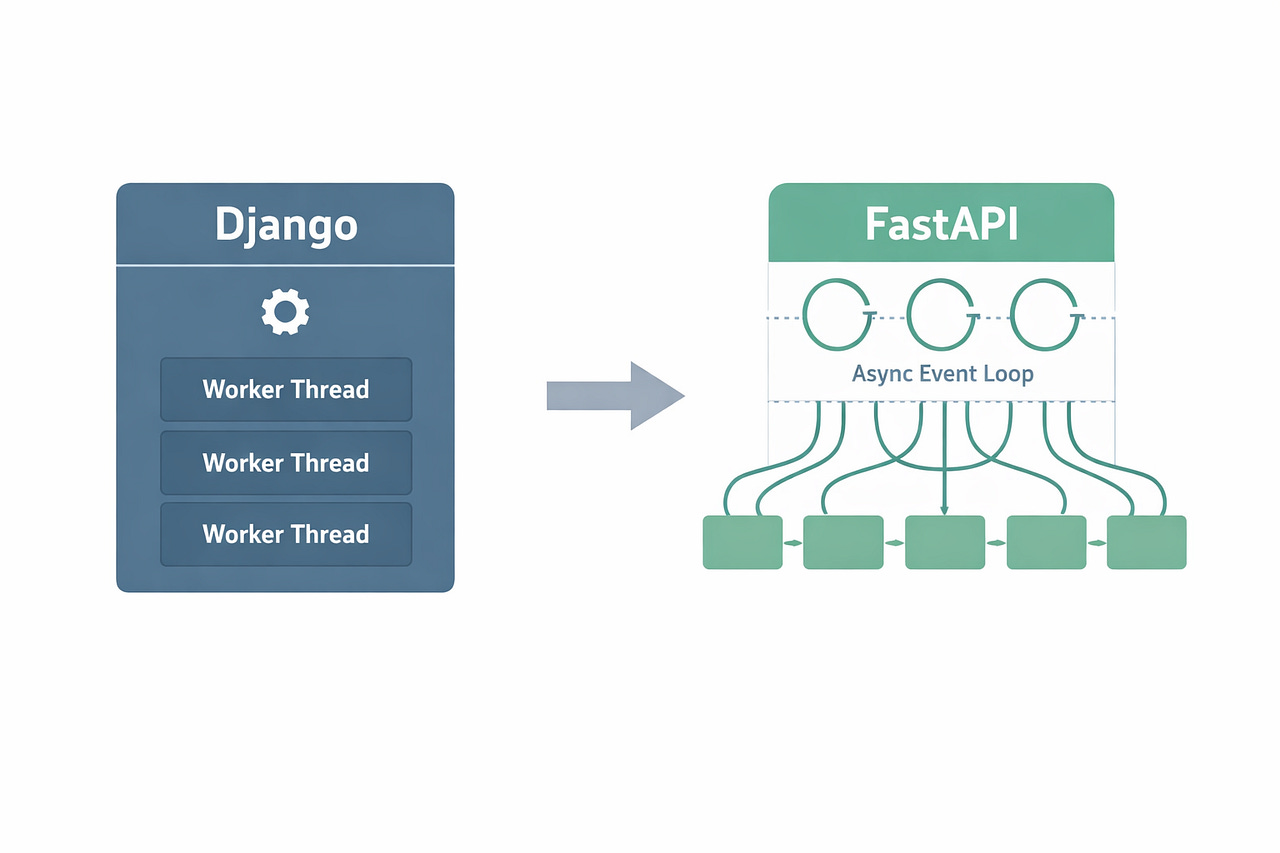
I didn’t wake up one morning and decide Django was bad. Django paid my bills for three years. I shipped e-commerce platforms, internal dashboards, and multi-tenant SaaS products with it. Django is a workhorse.
But in late 2024, three of our services started choking. Not because Django is slow. Because the workload changed and Django wasn’t built for what we were asking it to do.
This is the story of what happened when we moved three production services from Django to FastAPI — what went well, what went wrong, and when I’d still pick Django without thinking twice.
The Problem: Our Backend Workload Shifted
Two years ago, most of our Python services were classic CRUD. User hits an endpoint, we query PostgreSQL, serialize the response, send it back. Django REST Framework handled this beautifully.
Then AI happened. Not in a buzzword way — in a “now every request hits an LLM API that takes 2–8 seconds to respond” way.
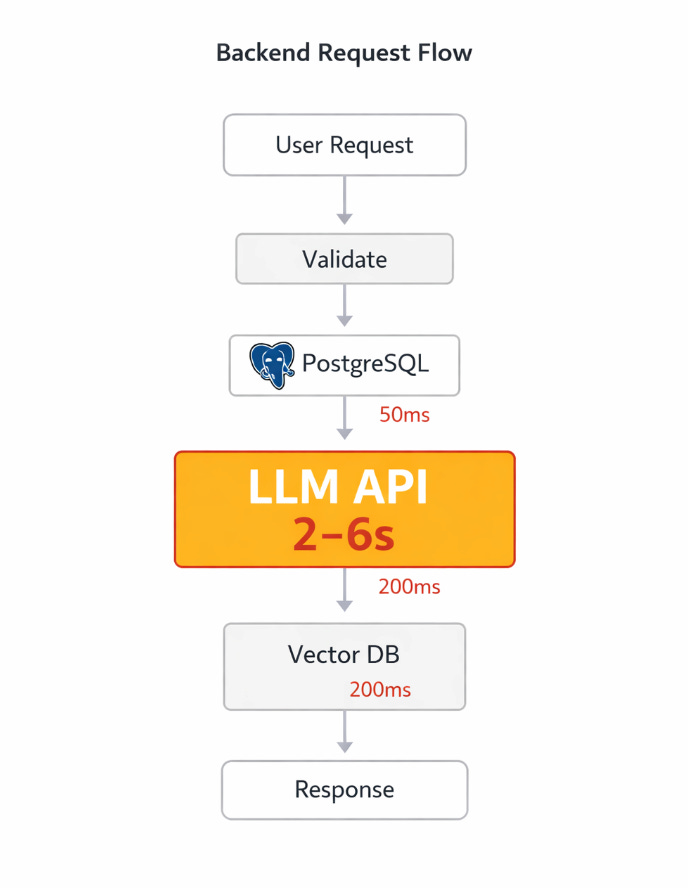
Here’s what our request flow started looking like:
User Request
→ Validate input (fast)
→ Query Postgres for context (50ms)
→ Call OpenAI API (2-6 seconds) ← this is where everything stalled
→ Call vector database for RAG (200ms)
→ Format response (fast)
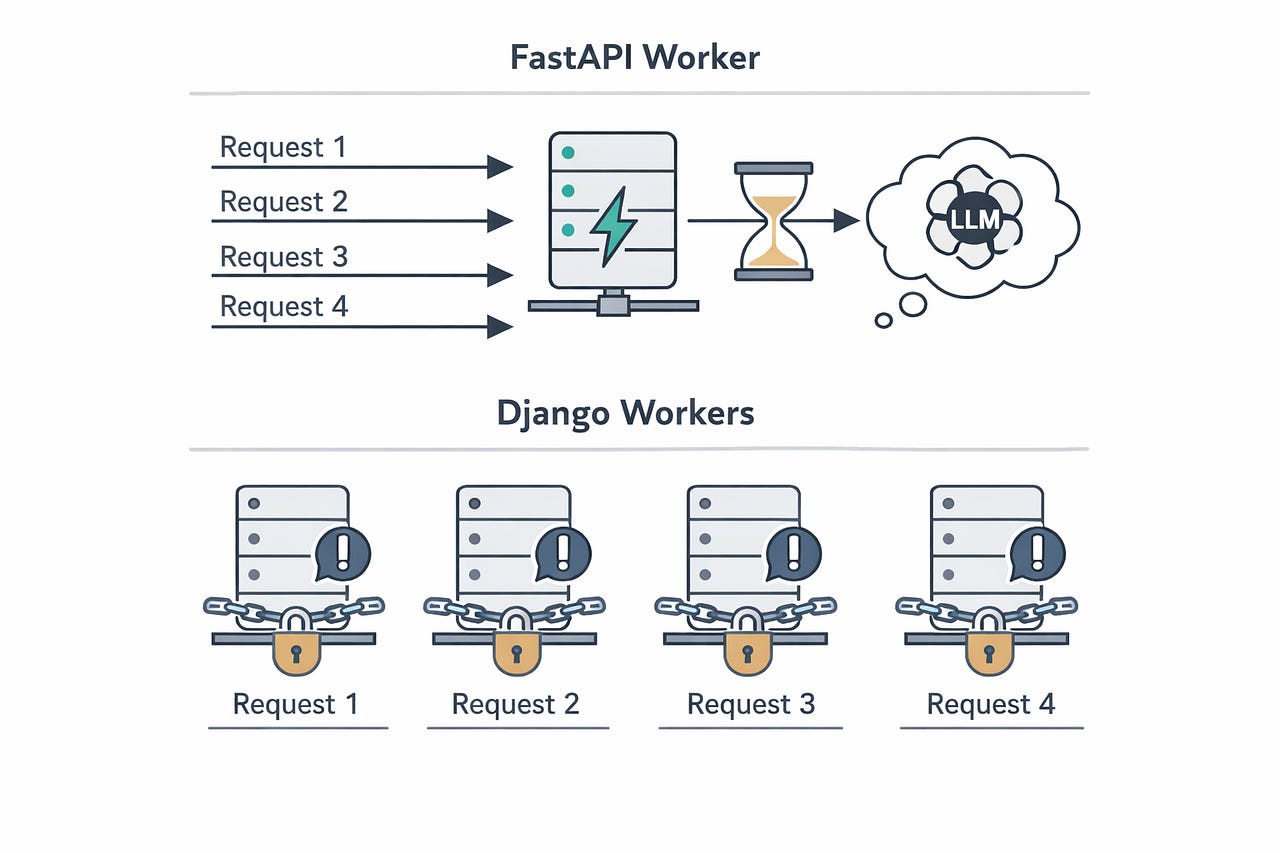
→ Return to userWith Django’s synchronous workers, each request occupied one worker process for the entire 3–8 seconds. Under 50 concurrent users, our 8-worker Gunicorn setup was completely saturated. Users saw timeouts. We threw more workers at it. Memory usage exploded.
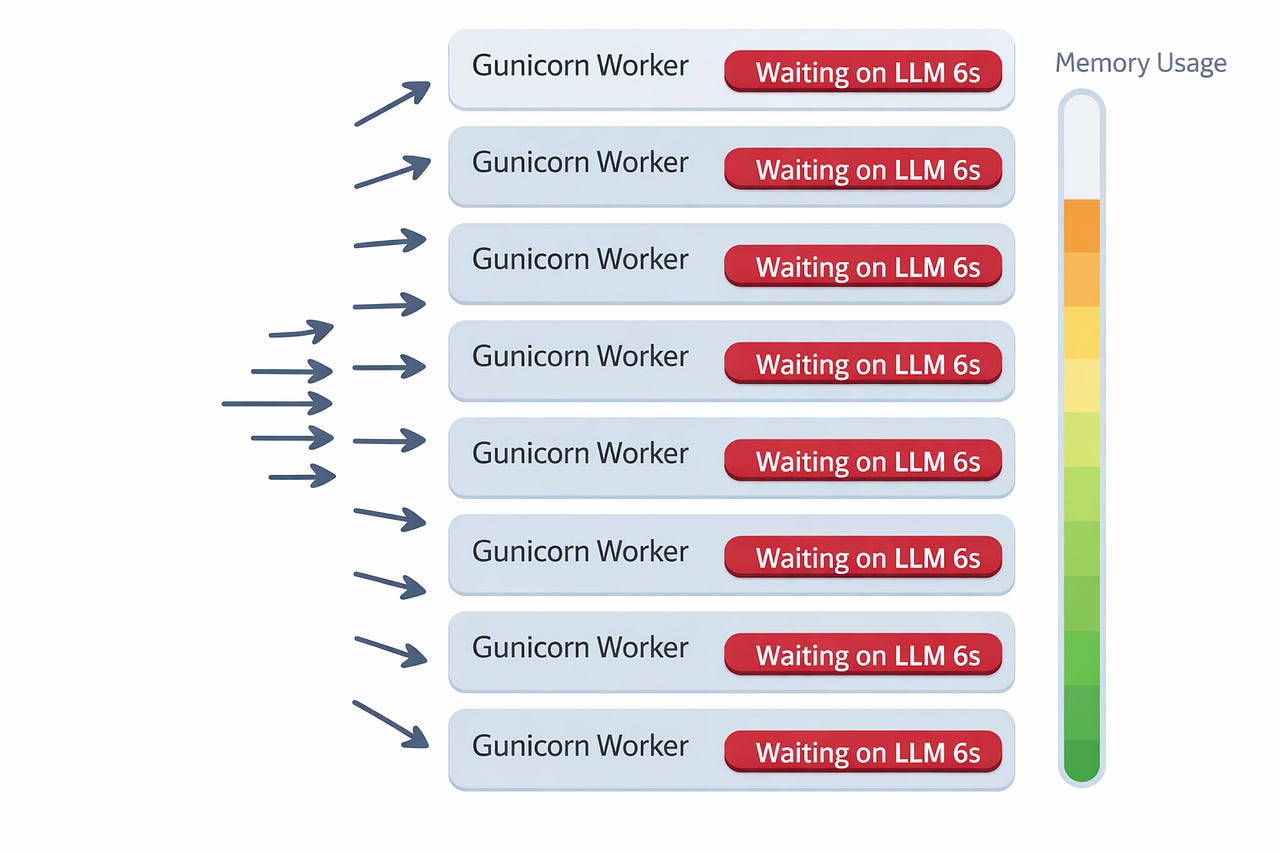
That’s when I started seriously looking at FastAPI.
Service #1: The AI Chat Backend
What it does: Takes user messages, retrieves context from a vector database, sends everything to an LLM, streams the response back.
Why Django struggled: Every request waited 3–6 seconds for the LLM. Django’s synchronous ORM was a bottleneck even after we added async views in Django 5.x. The ORM calls still ran in a threadpool under the hood — we weren’t getting real async.
The migration:
Django version (simplified):
# Django REST Framework — sync, blocking
class ChatView(APIView):
def post(self, request):
user_msg = request.data[”message”]
# This blocks a worker for the entire duration
context = VectorStore.objects.filter(
embedding__cosine_lte=(get_embedding(user_msg), 0.8)
)[:5]
response = openai.chat.completions.create(
model=”gpt-4”,
messages=[
{”role”: “system”, “content”: build_prompt(context)},
{”role”: “user”, “content”: user_msg}
]
)
ChatHistory.objects.create(
user=request.user,
message=user_msg,
response=response.choices[0].message.content
)
return Response({”reply”: response.choices[0].message.content})FastAPI version:
# FastAPI — async, non-blocking
@app.post(”/chat”)
async def chat(request: ChatRequest, user: User = Depends(get_current_user)):
# All I/O happens concurrently when possible
context = await vector_store.similarity_search(
query=request.message,
k=5
)
response = await openai_client.chat.completions.create(
model=”gpt-4”,
messages=[
{”role”: “system”, “content”: build_prompt(context)},
{”role”: “user”, “content”: request.message}
]
)
reply = response.choices[0].message.content
# Fire-and-forget: don’t make the user wait for DB write
background_tasks.add_task(save_chat_history, user.id, request.message, reply)
return ChatResponse(reply=reply)Result:
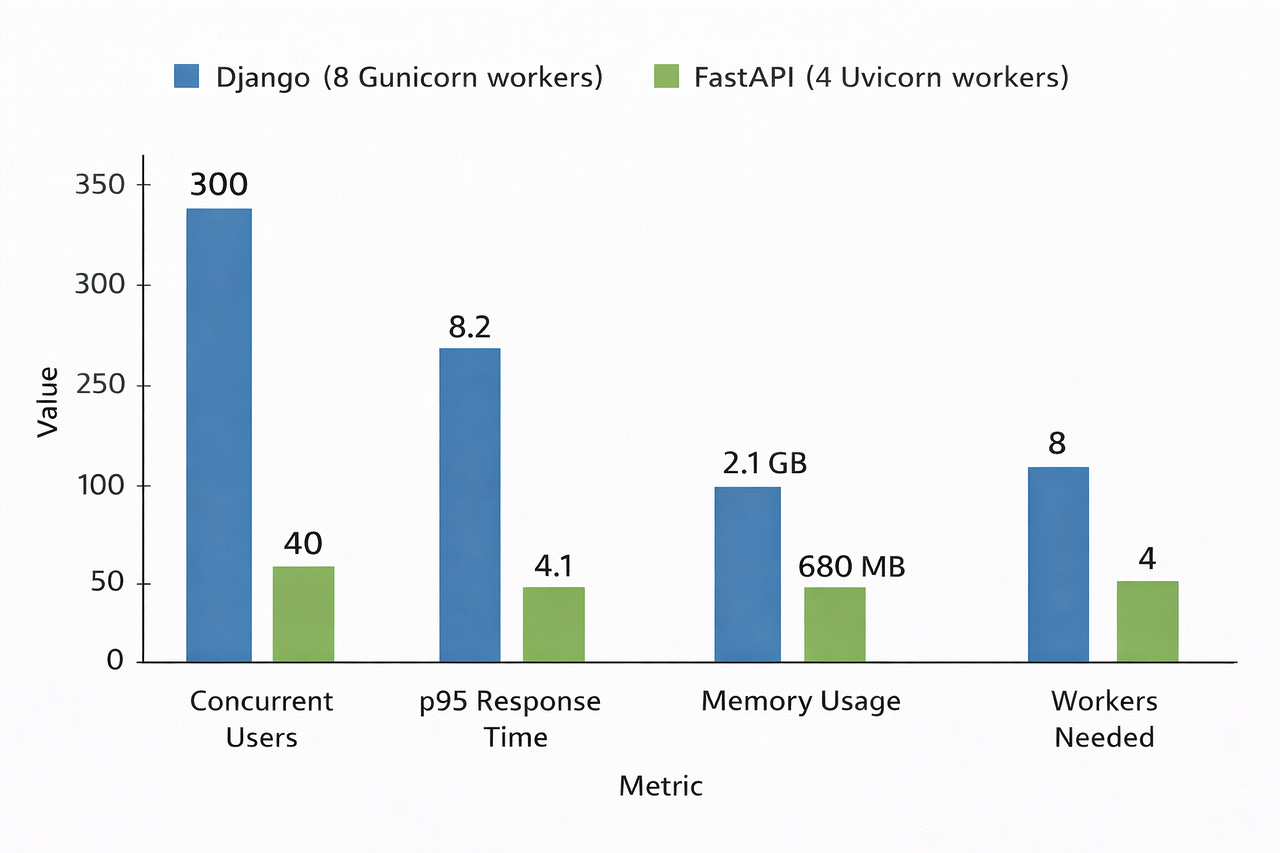
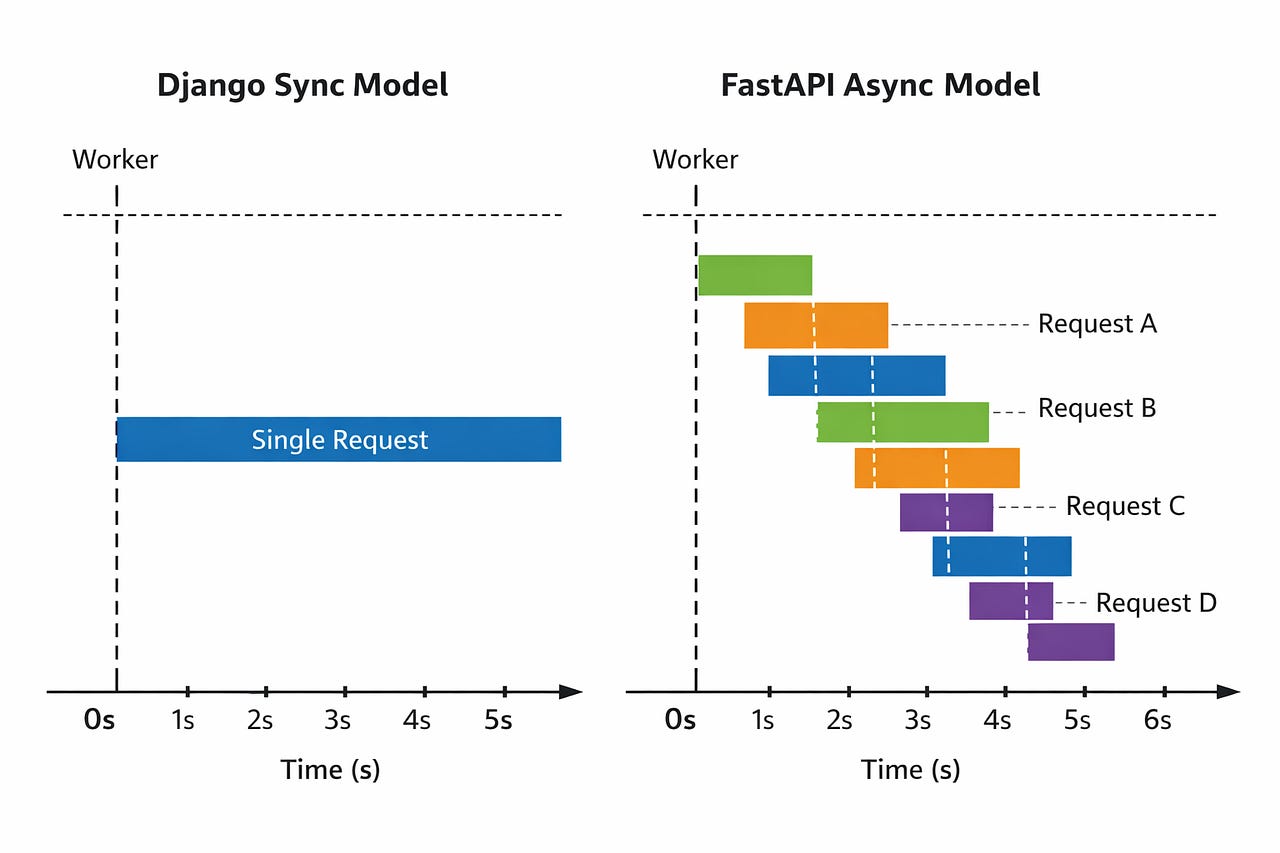
The numbers aren’t magic. FastAPI doesn’t make the LLM respond faster. What it does is release the worker while waiting for the LLM, so the same worker can handle dozens of other requests during that wait time. That’s the entire game with async.
Service #2: The Webhook Processor
What it does: Receives webhooks from Stripe, Slack, and three internal services. Validates the payload, processes the event, updates our database, and sometimes fires off notifications.
Why I thought FastAPI would help: High throughput, mostly I/O-bound, lots of concurrent incoming requests during peak hours.
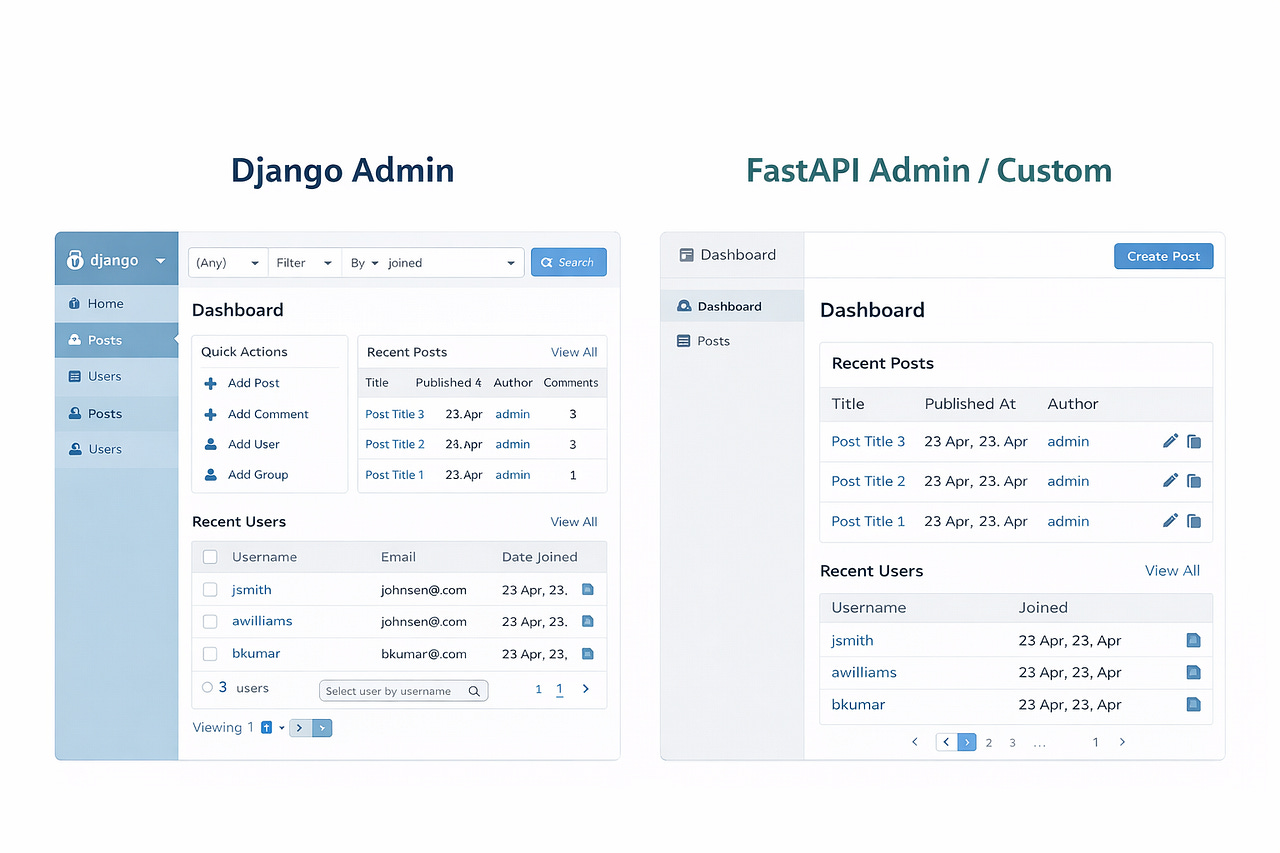
What actually happened: FastAPI handled the concurrency better, sure. But the migration was painful because this service was deeply married to Django’s ORM. We had 47 models, complex querysets with annotations and subqueries, and admin pages that the finance team used daily.
We spent 3 weeks rewriting models in SQLAlchemy. The finance team lost their admin interface. We had to build a lightweight admin panel with FastAPI-Admin, which covered maybe 60% of what Django Admin did out of the box.
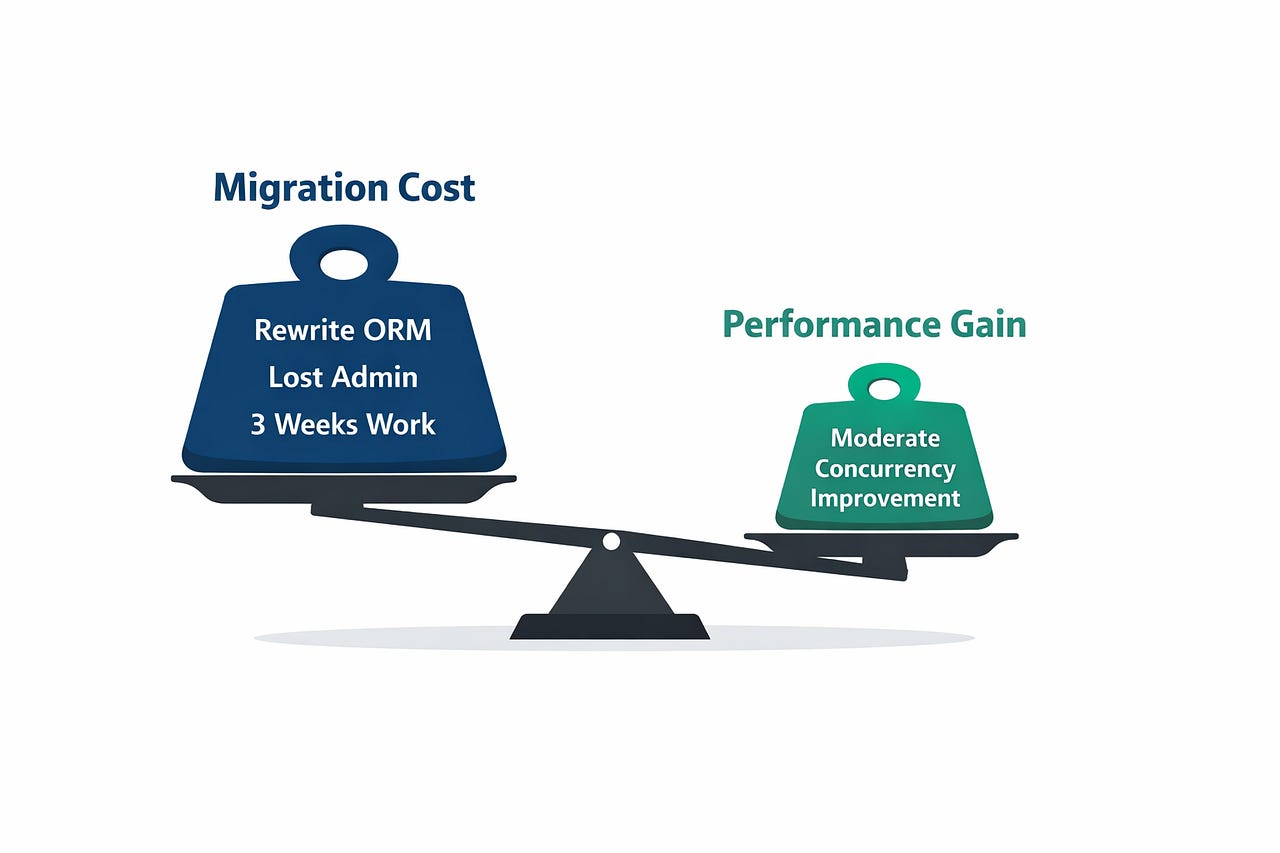
Honest assessment: The concurrency improvement was real but modest for this use case (webhooks are fast — they don’t have 6-second LLM calls). The migration cost was high. If I could redo this, I’d keep it in Django and put the high-concurrency webhook ingestion behind a thin FastAPI gateway that just queues events.
Lesson: Don’t migrate for the sake of migrating. Measure the actual bottleneck first.
Service #3: The Internal API Gateway
What it does: Sits between our frontend and 5 backend microservices. Aggregates data, handles auth, rate limiting.
Why FastAPI was the right call from day one: This service makes 3–5 outbound HTTP calls per request to gather data from downstream services. It’s pure I/O fan-out. This is FastAPI’s sweet spot.
@app.get(”/dashboard/{user_id}”)
async def get_dashboard(user_id: int, user: User = Depends(verify_token)):
# Fan-out: hit all services concurrently
profile, orders, notifications, recommendations = await asyncio.gather(
user_service.get_profile(user_id),
order_service.get_recent(user_id, limit=10),
notification_service.get_unread(user_id),
recommendation_service.get_for_user(user_id),
)
return DashboardResponse(
profile=profile,
orders=orders,
notifications=notifications,
recommendations=recommendations
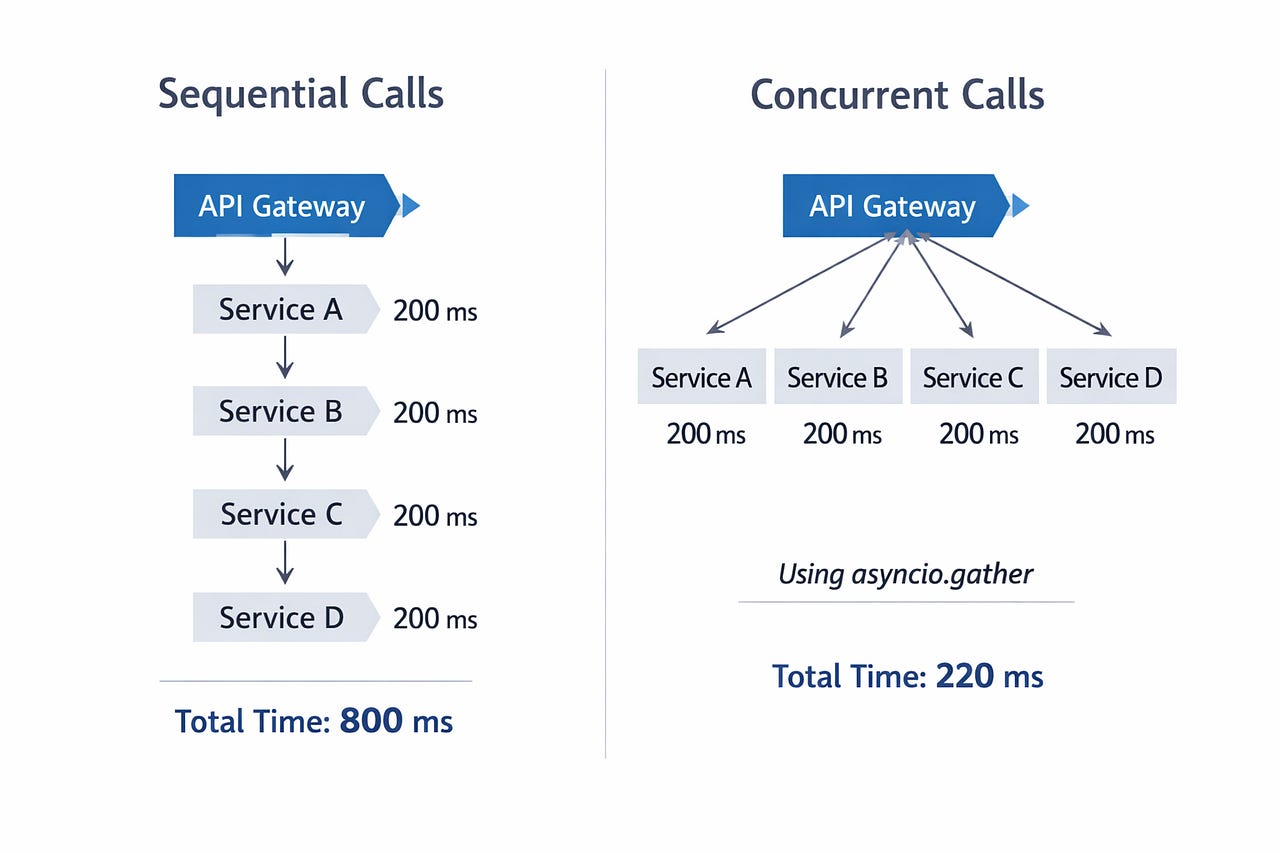
)In Django, these four HTTP calls would execute sequentially: ~800ms total. With asyncio.gather, they execute concurrently: ~220ms (limited by the slowest downstream service).
That’s not a framework benchmark. That’s a real user waiting 580ms less on every page load.
When I Still Pick Django Without Thinking Twice
After all this, I’m not a “FastAPI for everything” person. Here’s my decision framework:
Pick Django when:
Your app is database-heavy CRUD (content platforms, e-commerce, dashboards)
You need a production-ready admin interface yesterday
Your team knows Django and deadlines are tight
You’re building a monolith (Django is excellent for monoliths)
You need battle-tested auth, permissions, and middleware out of the box
Pick FastAPI when:
Your service calls external APIs, LLMs, or other microservices
You need to handle high concurrent connections with limited resources
You’re building an API-only service (no templates, no admin)
You want automatic OpenAPI docs that frontend teams can use immediately
You’re doing streaming responses (SSE, WebSocket)
The “it depends” zone:
If you need both CRUD admin and some async endpoints, consider Django with a FastAPI sidecar for the async-heavy routes
If you’re starting fresh and your team is comfortable with SQLAlchemy, FastAPI gives you more flexibility for future async workloads
The Numbers That Actually Matter
After 14 months running both in production, here’s what I track:

That last row matters. Async Python debugging is significantly harder than sync debugging. Stack traces are less readable. Race conditions appear. await in the wrong place silently kills performance. If your team isn’t comfortable with async Python, budget extra time for debugging.
What I’d Tell Myself 14 Months Ago
Don’t migrate working Django services just because FastAPI is shiny. Migrate when you’ve measured an actual performance bottleneck caused by synchronous I/O.
The Django ORM is a feature, not a limitation. SQLAlchemy is more flexible, but Django’s ORM + migrations + admin is an unmatched developer experience for data-heavy apps.
FastAPI’s real superpower isn’t speed — it’s concurrency. A single FastAPI worker doing I/O-bound work can handle what 8–10 Django workers handle. That’s where the savings come from.
4. Pydantic is worth the price of admission alone. Request validation, response serialization, settings management — Pydantic V2 is incredibly fast and changes how you think about data flow in Python.
5. The best architecture might be both. Django for your core product. FastAPI for your AI layer, API gateway, or any service that fans out to external APIs.
One Takeaway

If you’re a Python backend developer in 2026, you need to be comfortable with both Django and FastAPI. Not because one is better — because they solve different problems. The senior move is knowing which tool fits which workload, not having a favorite.
The workload decides. Not the hype.
Thanks for reading! ❤
I’m a Backend Tech Lead writing about real production experience — no theory, no fluff. If this was useful, I’ll be publishing daily for the next 30 days. Follow along.
Next up: “The Async Python Trap: Why Your ‘Fast’ API Is Slower Than You Think”