
The CAP Theorem Explained Simply
Understanding distributed systems trade-offs

I was reviewing a pull request from one of my team members. The code looked clean, tests were passing, but something felt off. He had built a synchronous replication system that waited for all three database replicas to confirm writes before returning success to the user.
“This will be slow,” I commented.
“But it guarantees consistency,” he replied.
“What happens when one replica goes down?”
Silence.
This is the exact moment most backend engineers discover the CAP theorem. Not in a textbook, but when their perfectly designed system starts breaking in production.
What Is CAP Theorem?
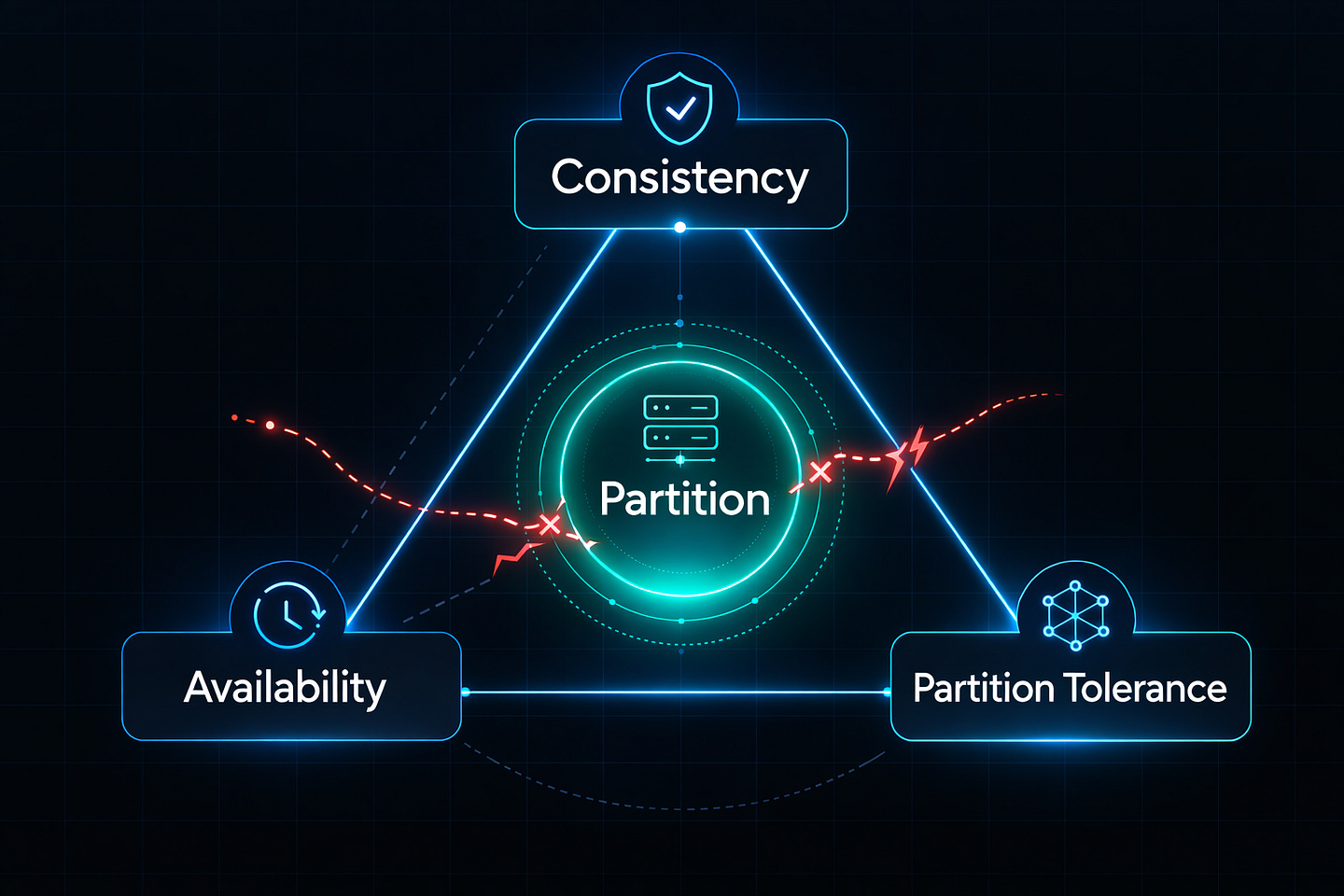
The CAP theorem says you can only pick two out of three guarantees in a distributed system:
Consistency: Every node shows the same data at the same time
Availability: Every request gets a response (success or failure)
Partition Tolerance: The system works even when network connections fail
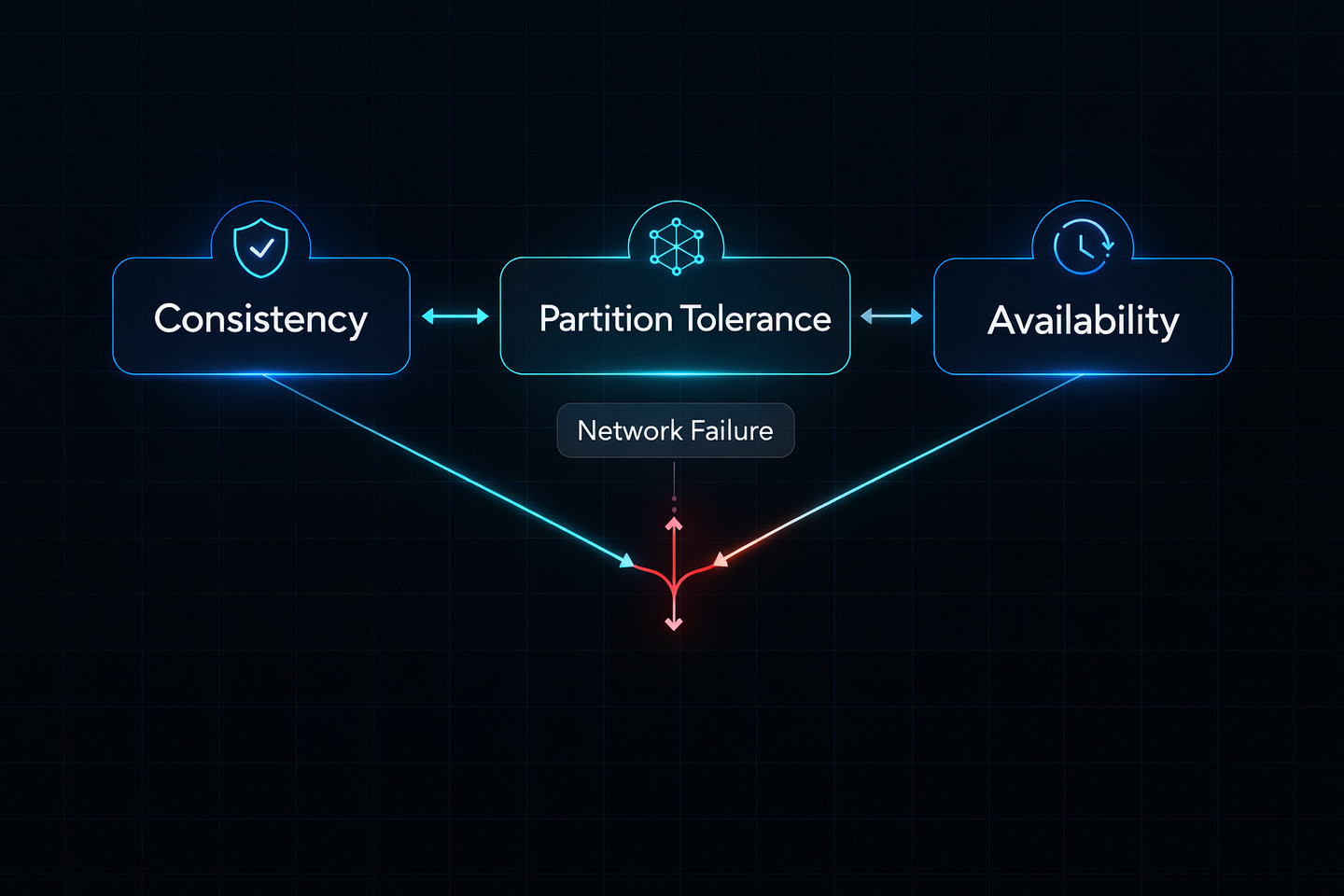
When network problems happen (and they always do), you must choose: consistent data or available service. You cannot have both.
Why This Matters
Let me show you what this looks like in real systems.
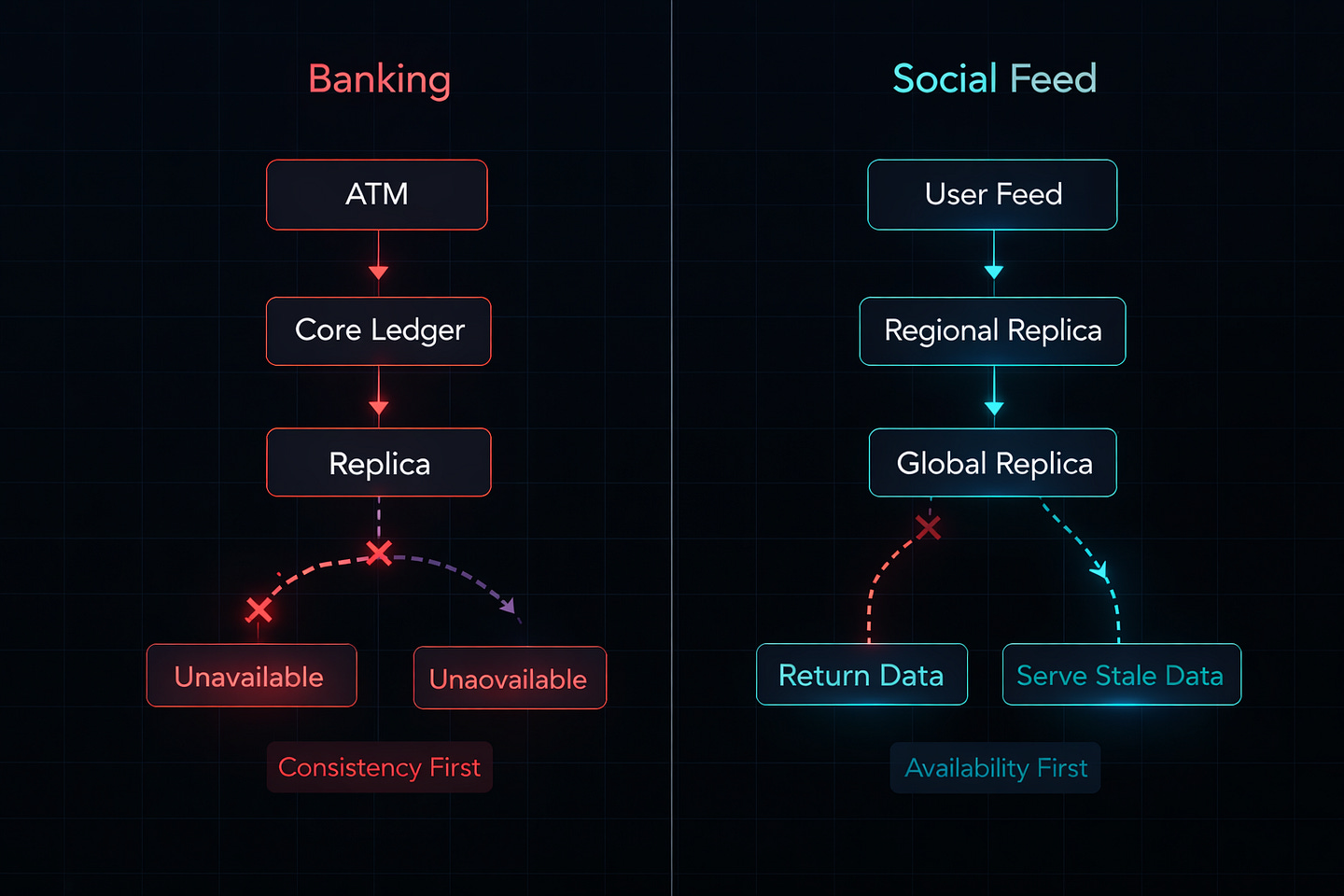
The Banking System (Choosing CP)
Your bank’s ATM denies your withdrawal. You know you have money, but the machine says “Service temporarily unavailable.” Frustrating, right?
Here’s what actually happened: The ATM lost connection to the central database. Instead of guessing your balance (which could let you overdraw), it shut down. The bank chose Consistency over Availability.
This makes sense because:
Wrong account balances destroy trust
Legal problems arise from incorrect transactions
A few minutes of downtime beats data corruption
The Social Media Feed (Choosing AP)
You like a post on Instagram. Your friend looks at the same post and sees a different like count. You see 1,247 likes. She sees 1,251 likes. Both numbers are “correct” for that moment, just not synchronized yet.
Instagram chose Availability over Consistency because:
Users expect instant responses
Slight data delays don’t matter much
Engagement drops if the app feels slow
Perfect sync isn’t worth the performance cost
The Real Trade-Off

Let’s break down what happens during a network partition (when servers cannot talk to each other).
Option 1: CP Systems (Consistency + Partition Tolerance)
Request comes in
↓
Can I reach all replicas?
↓ NO
Return error to user
Wait for network recoveryExamples: Traditional banks, payment processors, inventory systems
When to use: Money, healthcare records, legal documents
Option 2: AP Systems (Availability + Partition Tolerance)
Request comes in
↓
Can I reach all replicas?
↓ NO
Use available replica
Return data to user
Sync later when network recoversExamples: Social media, content delivery, analytics dashboards
When to use: User engagement matters more than perfect accuracy
Understanding The Third Option
You might ask: “Why not CA (Consistency + Availability)? Just skip Partition Tolerance.”
This sounds logical until you realize: network failures are not optional. They happen. Cables break. Routers crash. Data centers lose power. AWS has outages.
Ignoring partition tolerance means your system completely breaks during network issues. It’s like building a car without brakes because you plan to drive carefully.
Real Database Examples
Let’s look at actual databases and their CAP choices.
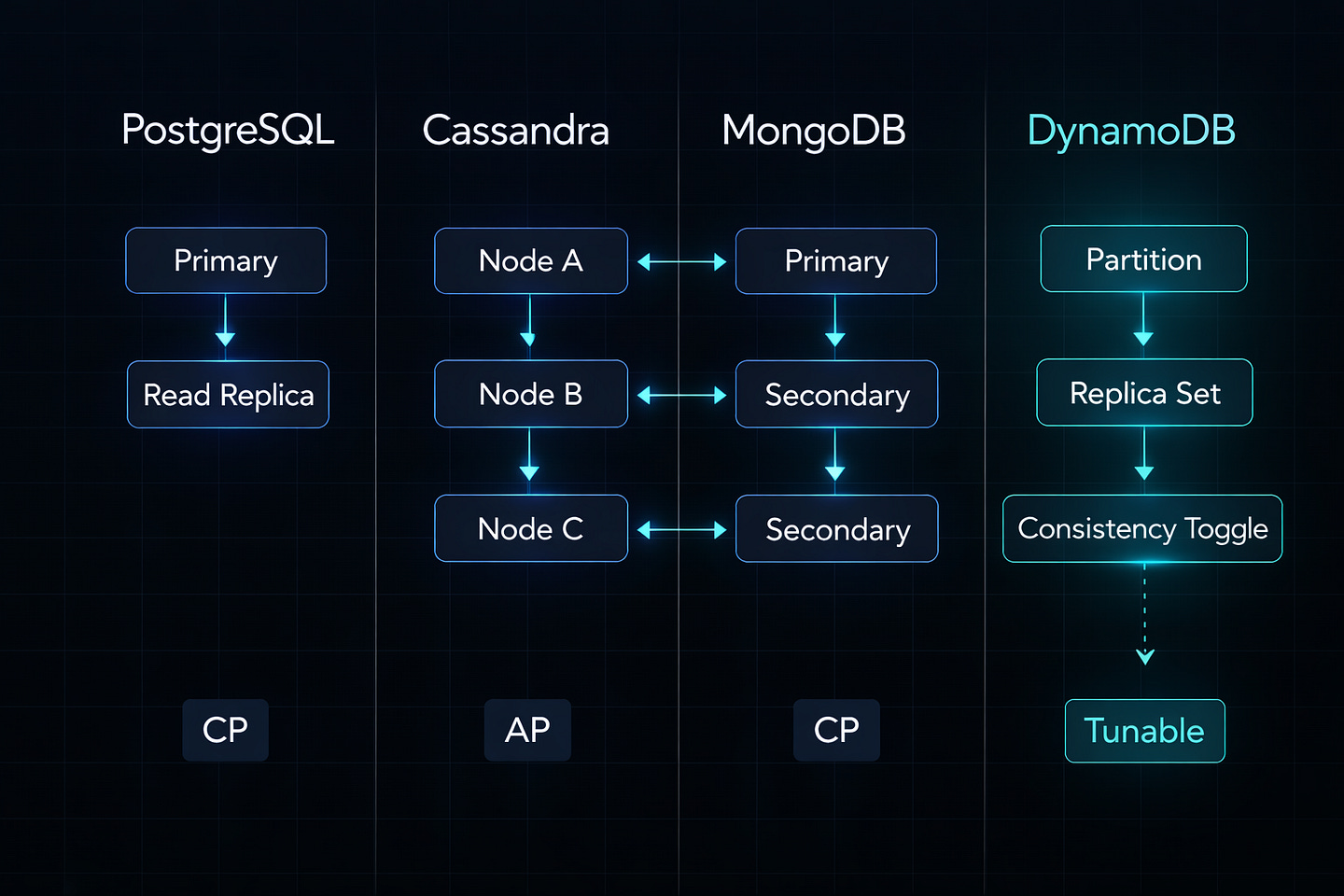
PostgreSQL (Traditional Setup)
Type: CP System
How it works:
Single master database
Writes go to master only
Reads can use replicas
If master is unreachable, writes fail
Trade-off: High consistency, but single point of failure
Cassandra
Type: AP System
How it works:
Data spreads across multiple nodes
No single master
Accepts writes even during network splits
Eventual consistency model
Trade-off: Always available, but temporary inconsistencies
MongoDB (Configured Properly)
Type: CP System
How it works:
Replica sets with primary/secondary nodes
Primary handles writes
If primary unreachable, elections pause writes
Majority agreement required
Trade-off: Consistency guaranteed, availability depends on quorum
Tunable Consistency: The Modern Approach
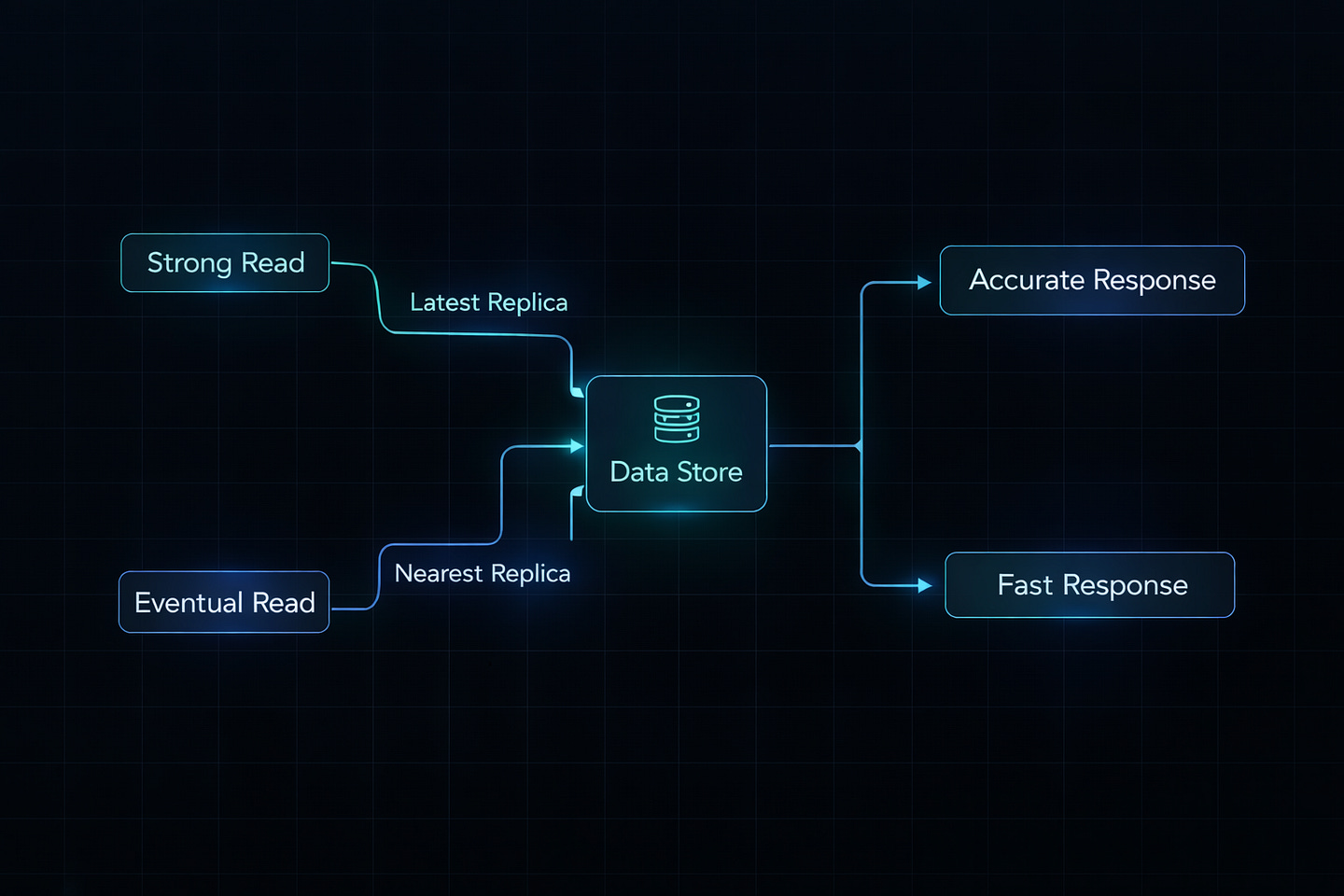
Modern systems don’t just pick one mode forever. They let you adjust per operation.
Example: DynamoDB Consistency Levels
Strong Consistency Read:
response = table.get_item(
Key={’id’: ‘123’},
ConsistentRead=True # Wait for latest data
)Use for: Account balances, inventory checks
Eventual Consistency Read:
response = table.get_item(
Key={’id’: ‘123’},
ConsistentRead=False # Accept slightly stale data
)Use for: User profiles, product descriptions
This flexibility lets you optimize each part of your application differently.
Practical Decision Framework
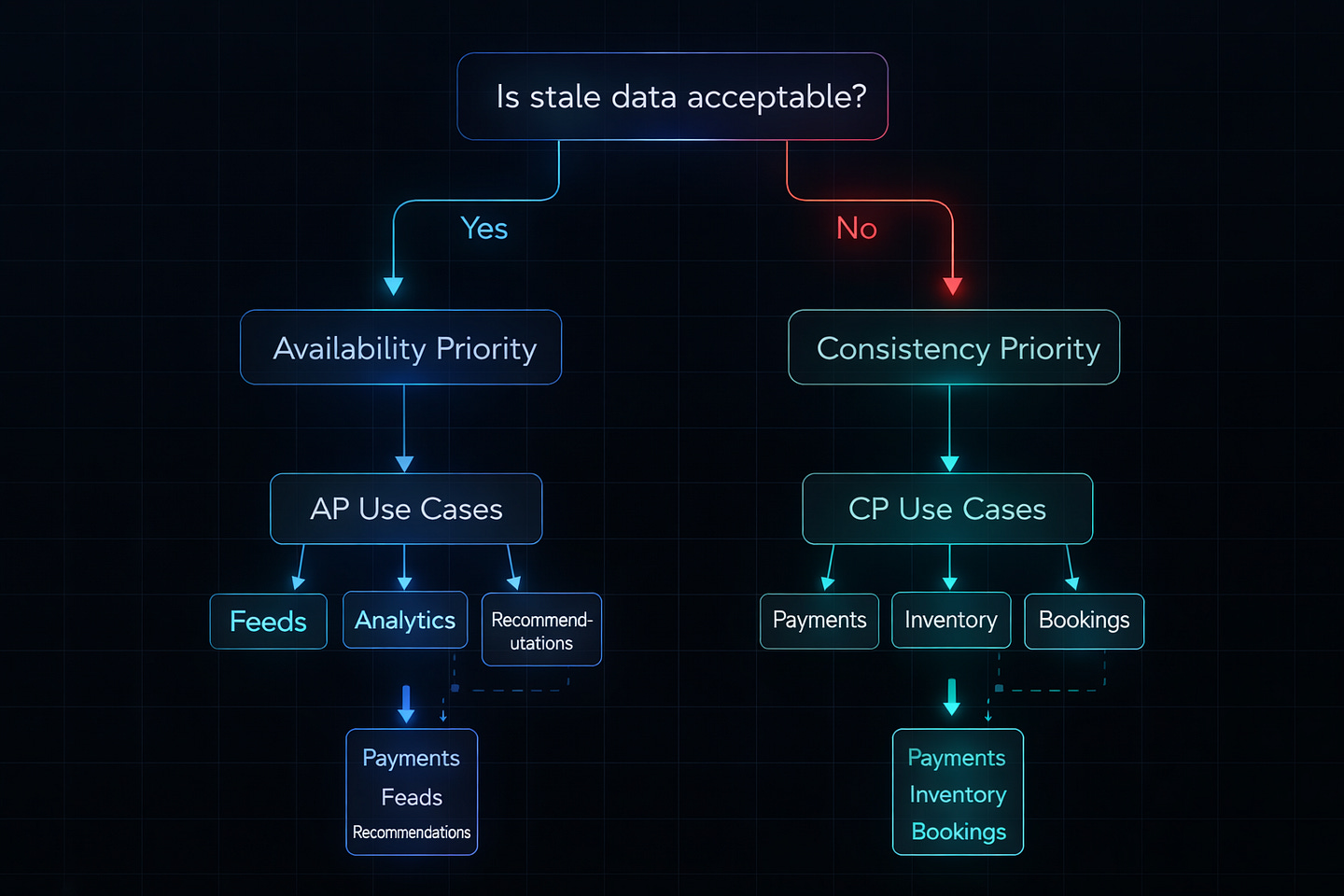
When designing your system, ask these questions:
Question 1: What breaks if data is stale?
Nothing critical → Choose AP (Availability)
Social feeds
Recommendation engines
View counts
Money or safety → Choose CP (Consistency)
Payment processing
Medical records
Stock trading
Question 2: What’s worse for users?
Slow/unavailable service → Choose AP
Consumer apps
Content platforms
Analytics dashboards
Wrong information → Choose CP
Banking
E-commerce inventory
Booking systems
Question 3: Can you handle conflicts later?
Yes, easy to merge → Choose AP
Shopping carts
Collaborative documents
User preferences
No, conflicts are complex → Choose CP
Financial transactions
Reservation systems
Sequential operations
Common Mistakes I See
Mistake 1: Over-Engineering for Consistency
A startup building a todo app implemented synchronous replication across 5 database replicas. Their app became slow and complex. Todo items don’t need bank-level consistency.
Lesson: Match your consistency needs to your actual requirements.
Mistake 2: Assuming Perfect Networks
A team designed their microservices assuming services always communicate perfectly. First major outage lasted 6 hours because nothing handled network failures gracefully.
Lesson: Always design for network partitions. They will happen.
Mistake 3: Ignoring Latency
Choosing strong consistency without understanding the performance cost. Users abandoned checkouts because each operation took 3+ seconds waiting for global consensus.
Lesson: Measure the impact. Sometimes “good enough” consistency is actually better.
The Spectrum Mindset
Modern engineers think in spectrums, not binaries:
Instead of: “My system is CP” Think: “My payment flow is CP, my feed is AP, my cache is AP”
Instead of: “Always strong consistency” Think: “Strong consistency for writes, eventual for reads”
Instead of: “Never sacrifice availability” Think: “Sacrifice availability for critical paths only”
Building for CAP in Practice
Here’s how to actually apply this:
Step 1: Map Your Data
Create a table:

Step 2: Choose Your Tools
Match databases to requirements:
Need CP: PostgreSQL, MongoDB, HBase Need AP: Cassandra, DynamoDB, Couchbase Need both: Use different databases for different data types
Step 3: Implement Gracefully
Don’t just fail. Handle degradation:
def get_user_balance(user_id):
try:
# Try strong consistency first
return db.get_with_consistency(user_id, level=’strong’)
except PartitionError:
# During partition, deny transaction
# Don’t guess the balance
raise ServiceUnavailableError(”Please try again”)def get_user_feed(user_id):
try:
# Try latest data first
return cache.get_fresh(user_id)
except PartitionError:
# During partition, serve cached data
# Slightly stale is better than nothing
return cache.get_stale(user_id)Beyond CAP: PACELC
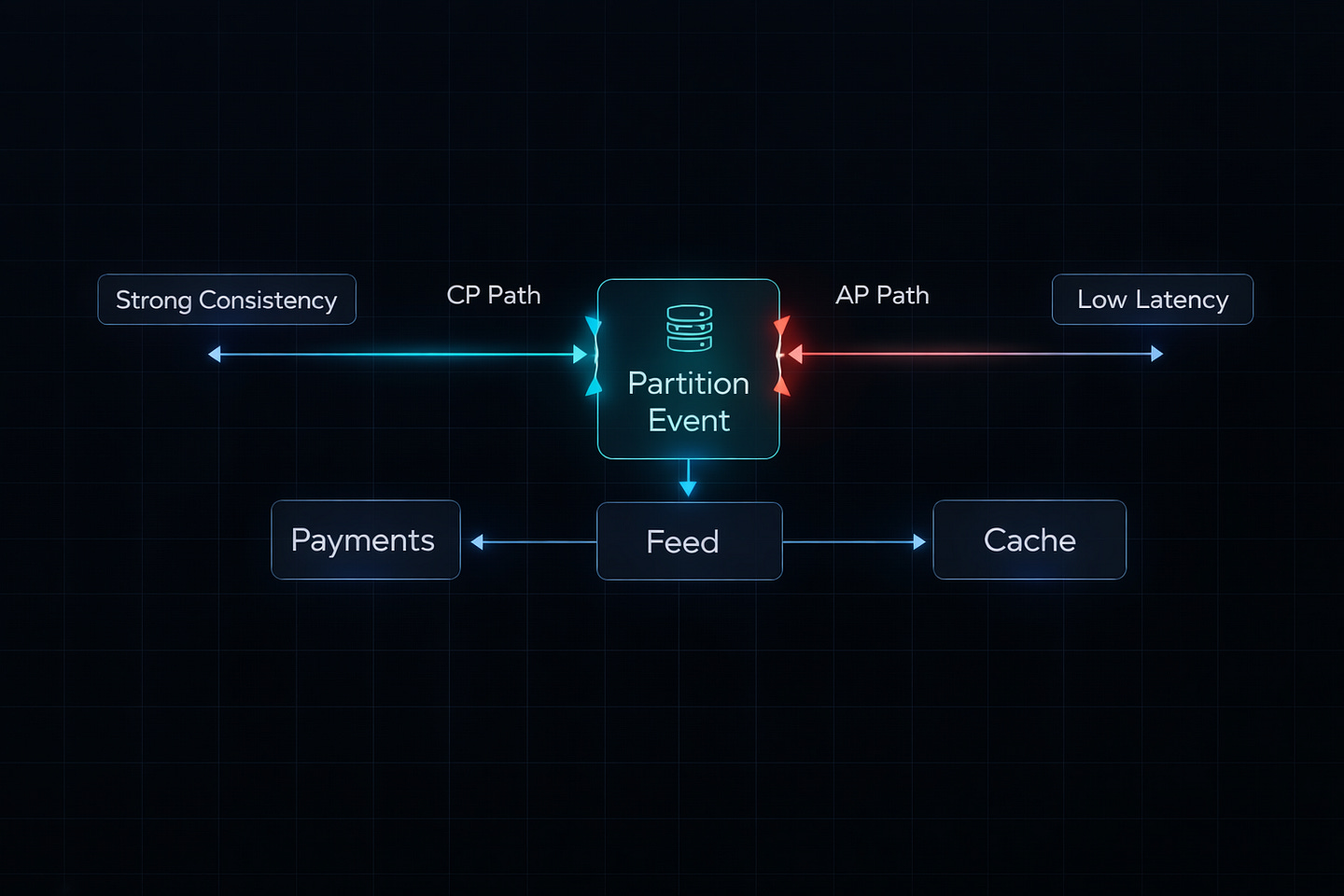
CAP theorem only covers partition scenarios. PACELC extends it:
“If Partition, choose A or C. Else (normal operation), choose Latency or Consistency”
This matters because even without partitions, you trade consistency for speed:
High Consistency + High Latency: Wait for all replicas Low Consistency + Low Latency: Use nearest replica
Most systems want low latency during normal operation, so they choose eventual consistency even when networks are healthy.
The Future: CRDTs
Conflict-free Replicated Data Types (CRDTs) are changing the game. They’re mathematical structures that merge automatically without conflicts.
Example: A counter that multiple people increment
Traditional approach: Lock, increment, unlock (slow)
CRDT approach: Everyone increments locally, values merge later (fast)
CRDTs power collaborative tools like Figma and Google Docs. They’re still complex to implement, but they push the boundaries of what’s possible.
What Actually Matters
The CAP theorem isn’t about limitations. It’s about understanding trade-offs so you can make intelligent decisions.
Good engineers don’t try to “beat” CAP. They:
Understand their actual requirements
Choose appropriate consistency levels
Design for network failures
Monitor and measure impact
Adjust based on real user needs
Your system doesn’t need to be perfect. It needs to be right for your use case.
Key Takeaways
1. Network partitions always happen Design for them from day one.
2. Different data needs different consistency Don’t treat everything the same.
3. Availability vs Consistency is a spectrum Tune it per operation, not system-wide.
4. Users care about experience Sometimes “fast and slightly stale” beats “slow and perfect.”
5. Monitor and measure Your assumptions will be wrong. Let data guide you.
The next time you design a distributed system, you won’t ask “How do I get all three?” You’ll ask “Which two matter most for this specific feature?”
That’s when you know you’ve really understood CAP.
What’s Next?
If you found this valuable, I’d appreciate your help. Hit the like ♥️ to help others discover this article. Share it with engineers who need to understand distributed systems.
Subscribe if you want more backend engineering deep dives like this delivered to your inbox. I write about Django, Python, databases, and system design—the real stuff we deal with in production.
Your 10 minutes reading this means a lot. Let’s build smarter systems together.